Le persone hanno una cosa in comune: sono tutte differenti.
Robert Zend
Esistono due tipi di acidi nucleici: l’RNA (acido ribonucleico) e il DNA (acido desossiribonucleico). Così chiamati perché particolarmente abbondanti nel nucleo delle cellule, gli acidi nucleici sono le molecole che contengono l’informazione genetica, cioè l’insieme delle istruzioni necessarie alla fabbricazione delle proteine e degli enzimi che andranno a formare l’organismo che li ospita.
5.3.1. L’RNA
Questa molecola polimerica è implicata in vari ruoli biologici, di codifica, decodifica, regolazione ed espressione dei geni. In generale si può dire che provvede a tradurre l’informazione genetica, contenuta nel DNA, nel linguaggio (cioè nella struttura) delle proteine.
Tecniche relativamente recenti applicate sull’RNA, in particolare sul cosiddetto RNA messaggero (mRNA), vengono usate per applicazioni particolari ed estremamente interessanti dal punto di vista forense. L’impiego è rivolto all’identificazione dei fluidi biologici, trattandosi di un tipo di acido nucleico che ha a che fare con l’espressione genica. Differenti tipi cellulari del nostro corpo contengono, infatti, varianti di mRNA che talvolta possono essere uniche per quei tipi cellulari, per esempio per gli spermatozoi verso le cellule epiteliali. L’mRNA è molto meno stabile rispetto al DNA, essendo a singola elica e quindi sottoposto a processi degradativi rapidi da parte degli enzimi. La tecnica di analisi è poi più lunga, richiedendo alcune fasi di laboratorio più complesse.
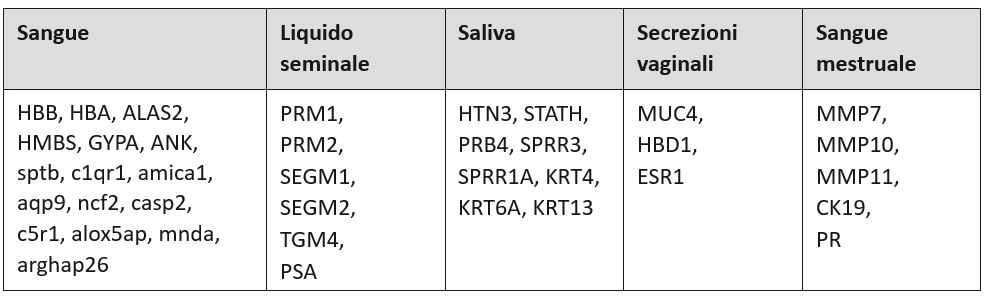
Nella tabella è riportata una lista dei geni maggiormente rappresentati a seconda dei tipi cellulari [1].
Il protagonista della genetica forense è, comunque, il DNA.
5.3.2 Il DNA nucleare
È il depositario dell’informazione genetica, la memoria biologica, ciò che permette la nascita di un essere umano da un uomo e una donna (anzi, è meglio dire da una cellula uovo e da un gamete maschile). Le unità fondamentali sono dette geni, sezioni del DNA che hanno la proprietà di contenere l’informazione necessaria per la costruzione attraverso l’assemblaggio di amminoacidi, di proteine ed enzimi, cioè di tutto il necessario per determinare lo sviluppo degli organismi. L’influenza reciproca e complessa di geni e proteine determina poi l’affermazione di certi caratteri rispetto ad altri, comprese le sfumature che apprezziamo nelle differenze tra individui.
La gran parte del DNA, oltre il 98%, non è però deputata alla formazione di proteine e dunque ha una funzione per molti aspetti ancora sconosciuta. Proprio in questa parte del cosiddetto «DNA spazzatura» sono concentrate le differenze tra gli individui, non espresse nelle caratteristiche somatiche visibili, ma misurabili a livello molecolare. È la cosiddetta «variabilità genetica», ciò che ci rende individuabili, unici rispetto a tutte le altre persone.
Uno dei compiti del genetista forense è quindi quello di caratterizzare queste differenze, studiandone alcune regioni geniche particolari, con le tecnologie che la biologia molecolare gli mette a disposizione: tecniche sempre più fini e in grado di individuare differenze minime tra due DNA da comparare, promettendo, addirittura, di riuscire là dove la genetica forense finora si è arresa, di fronte al prodigio della natura che ha dotato alcune persone, i gemelli monozigoti, del medesimo, identico DNA. Dal punto di vista molecolare il DNA è una delle molecole meno reattive e chimicamente più inerti del mondo vivente ed è per questo motivo che resta relativamente stabile anche in macchie biologiche essiccate. L’alfabeto genetico è piuttosto semplice, contando soltanto quattro lettere (basi): adenina (A), citosina (C), guanina (G) e timina (T).
Si tratta di una molecola lunghissima a forma di doppia elica che, se svolta, misurerebbe circa due metri. Se venisse allineato tutto il materiale genetico delle cellule di una persona si raggiungerebbe la distanza di ben 20 milioni di chilometri.
In una molecola di DNA umano sono presenti circa 3.300.000.000 di queste basi (3,3 x 109), un numero davvero enorme. Per fare un paragone si pensi al Grande Dizionario Enciclopedico della UTET nella versione completa composta da 20 volumi: ognuno di questi contiene circa 900 pagine, ogni pagina mediamente 73 righe e in ogni riga ci sono circa 100 lettere. Complessivamente esso contiene quindi circa 130 milioni di lettere. Occorrerebbero ben 25 di queste enciclopedie, cioè 500 volumi, per trascrivere tutte le basi presenti nel DNA contenuto in una singola cellula umana!
Così descritto in “DNA e Crimine“
Il DNA porta al proprio interno l’informazione genetica attraverso la quale gli organismi duplicano se stessi, producendo cellule identiche a quelle originarie. Il meccanismo con il quale il DNA si riproduce è molto preciso e si stima che appena una volta su un milione avvenga un errore, che la cellula tra l’altro è spesso in grado di riparare.
Ciascuno di noi possiede all’interno delle proprie cellule del sangue, della saliva, della pelle, ecc., un corredo cromosomico identico che dunque lo caratterizza in modo esclusivo, con la particolarità di essere stato trasmesso dalle generazioni precedenti e quindi di conservarne le caratteristiche di variabilità.
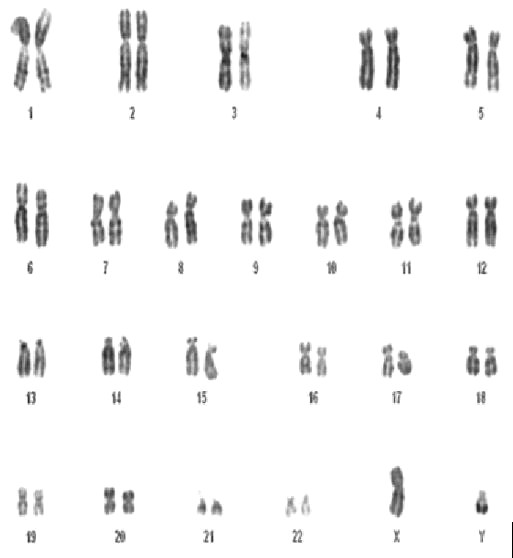
Il DNA è organizzato in strutture fisiche dette «cromosomi» o almeno è così che possiamo vederli in un particolare momento della sua duplicazione. Nel nucleo di una cellula umana ci sono 23 paia di cromosomi, 22 in comune tra uomo e donna (detti cromosomi autosomici e numerati da 1 a 22) e due determinanti il genere di appartenenza (detti cromosomi sessuali e indicati dalle lettere X e Y). Nella donna la coppia di cromosomi sessuali è XX, nell’uomo XY, per cui la differenza tra i sessi è dovuta proprio alla presenza del cromosoma Y nel genere maschile (o se si preferisce al fatto che le donne hanno due cromosomi X, ben il doppio dell’uomo!).
Per quanto sia possibile vedere i cromosomi, che hanno dimensioni da 0.2 a 20 µm, le piccole differenze morfologiche non consentono la discriminazione tra individui. Lo studio del cariotipo viene effettuato principalmente a fini medici, per l’individuazione di patologie. Per l’identificazione genetica si deve scendere a un livello di definizione molto maggiore, cercando un tipo di variabilità a livello molecolare. Si passa quindi dalle differenze strutturali, apprezzabili attraverso colture cellulari ed esami morfologici al microscopio, a quelle molecolari, che impiegano tecniche del tutto diverse indagando a livello più profondo la struttura molecolare del DNA.
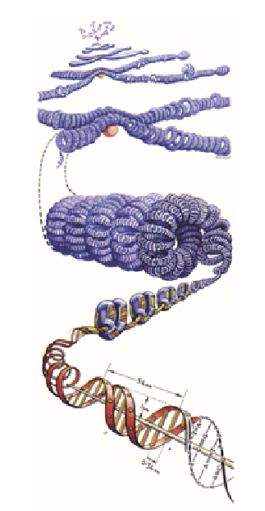
A fianco l’impacchettamento del DNA
Ciascuna coppia di cromosomi è stata infatti ereditata dai propri genitori biologici, con un assortimento casuale, secondo una logica che si perpetua, costante, da milioni di anni.
Ogni genitore contribuisce, a caso, con uno dei cromosomi autosomici; dunque un cromosoma 1 deriva dalla madre e l’altro cromosoma 1 dal padre. Un cromosoma 2 dalla madre e l’altro cromosoma 2 dal padre e così via fino a 22. La madre contribuisce poi con un cromosoma sessuale X, mentre il padre o con un cromosoma X. Dando vita quindi a un soggetto femminile o con un cromosoma Y originando un soggetto maschile).
È comunque conveniente non andare a studiare tutto il DNA di una cellula. Si tratta di più di 3 miliardi di paia di basi: ci vorrebbe troppo tempo, energia e denaro.

Se in una schermata video posso vedere insieme 3.000 basi e per fare un clic sul mouse impiego mezzo secondo, occorrerebbero più di 6 giorni per far scorrere tutta la sequenza delle basi contenute nel DNA di una singola cellula umana! Conviene quindi concentrarsi su poche schermate, contenenti però frammenti di DNA molto variabili tra le persone.
Il rettangolo indica un tratto di DNA variabile, quindi con differenze misurabili tra differenti soggetti.

I marcatori sono localizzati all’interno dei cromosomi in zone chiamate loci. Il termine indica, come recita l’art. 2 del regolamento di attuazione della legge sulla Banca dati, «la posizione fisica su un cromosoma di un gene o di un marcatore in una regione del DNA».
È come se il DNA fosse una lunghissima strada nella quale i numeri civici rappresentano i singoli loci, singole abitazioni che dall’esterno non svelano cosa c’è all’interno.
Il genetista forense sa che in alcuni «appartamenti» ci sono dei marcatori interessanti. Quindi vi accede riuscendo a svelarne il contenuto, con gli artifizi presenti nel laboratorio di biologia molecolare.
A fianco “La via del DNA”
È sufficiente dunque concentrare l’attenzione solo in alcune zone particolari di questa lunga macromolecola, settori nei quali si registra una variabilità elevata. Queste zone sono chiamate «marcatori genetici» o «polimorfismi».
In ciascun cromosoma, compresi i cromosomi sessuali, si possono dunque trovare, nello stesso locus, delle differenze a livello molecolare. Ognuna di queste forme (definite nella legge sulla Banca dati come «varianti del DNA presenti a uno stesso locus») [2] viene detta allele.
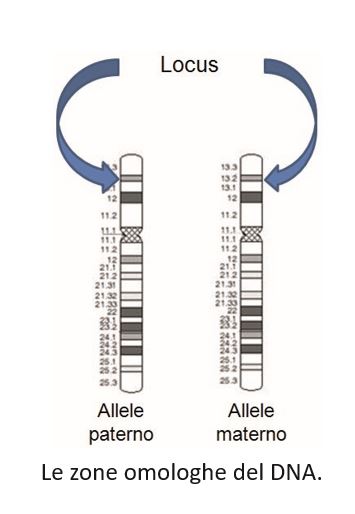
Per dare significato alla parola allele si immagini che ciascun tratto del DNA possa essere identificato come una parola della lingua italiana. Se si leggono diversi vocabolari, si apprezzerà che ogni autore fornisce una propria definizione per ciascun termine, pur conservandone il significato originario. Si può verificarlo chiedendo a un gruppo di volontari di scrivere la definizione di una parola di uso comune, per esempio «casa». Certamente non ci saranno due persone che daranno una definizione perfettamente identica, pur descrivendo in modo comprensibile la medesima cosa. In differenti loci del DNA è possibile identificare molte forme diverse, diversi alleli appunto. Proprio come accade per le parole della nostra lingua, per le quali possiamo fornire diverse definizioni alternative.
Esistono vari tipi di marcatori genetici, ma quelli che interessano i genetisti forensi sono principalmente di due tipi: di sequenza e microsatelliti.
I polimorfismi di sequenza sono quelli nei quali la variazione tra alleli è dovuta a una diversa sequenza, anche per una sola base. Come i seguenti tratti di DNA mitocondriale, dove sono indicate tre variazioni di altrettante basi (indicate in grassetto e sottolineate).
Allele 1 – GAT CAC AGG TCT ATC ACC CTA TTA ACC ACT CAC
Allele 2 – GAT CAG AGG TCT AAC ACC CTA TTA ACC ACT GAC
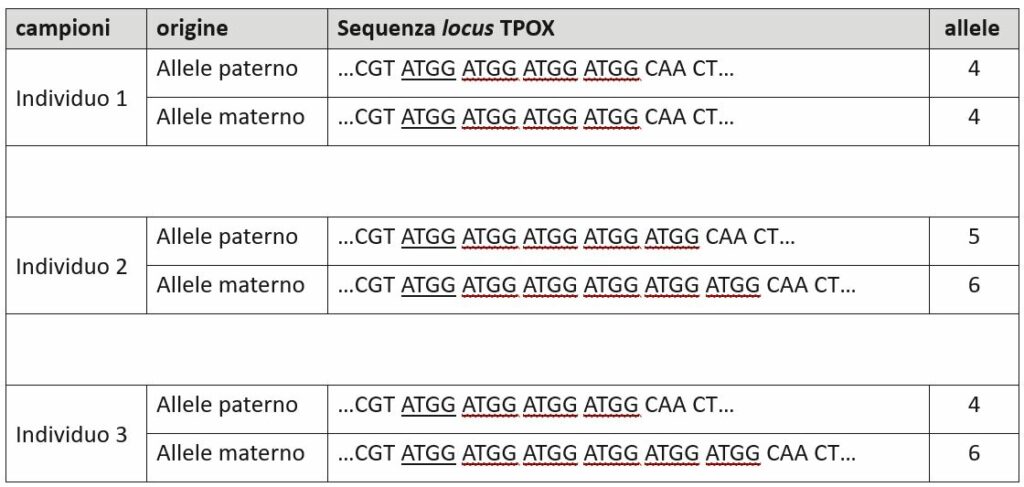
I marcatori più utilizzati per i profili genetici sono però i microsatelliti, conosciuti anche con la denominazione short tandem repeat (STR). In questo caso la differenza tra alleli deriva dalla lunghezza, oltre che dalla sequenza delle basi. Il nome particolare è dovuto al fatto che le varianti sono delle sequenze corte (1-5 paia di basi) che si ripetono in tandem. E’ come se il DNA fosse affetto da balbuzie in quei punti e, impuntandosi, ripetesse lo stesso motivo per un certo numero di volte. A fianco un esempio.
La nomenclatura per indicare gli alleli dei marcatori microsatelliti si basa sul numero di sequenze ripetute. In questo modo un’informazione piuttosto complessa come quella ottenuta dall’esame di un tratto di DNA viene classificata in modo semplice. Attraverso due numeri, uno per ciascun allele della coppia, a quel particolare locus [3].
Si esamini per esempio il marcatore D2S1338. Corrisponde ai seguenti dati di riferimento di una Banca dati genetica (localizzazione cromosoma 2 posizione 2q35 – Chr 2; 218.705 Mb – May 2004, NCBI build 35). Per esempio, in una persona sono state individuate queste forme alternative. Corrispondono alle sequenze sottolineate, TGCC e TTCC che si ripetono diverse volte, determinando frammenti di DNA di lunghezza diversa.
Allele 17
gcct tgcc tgcc tgcc tgcc tgcc tgcc ttcc ttcc ttcc ttcc ttcc ttcc ttcc ttcc ttcc ttcc ttcc ctc ctgca atcctttaac ttactgaata actca
Allele 19
gcct tgcc tgcc tgcc tgcc tgcc tgcc ttcc ttcc ttcc ttcc ttcc ttcc ttcc ttcc ttcc ttcc ttcc ctcctgca atcctttaac ttactgaata actca
L’assetto genetico di questo marcatore, per quella persona, si descriverà così:
D2S1338 – 17, 19 (in genere si indica per primo l’allele con numero inferiore)
In questo caso si dice che l’assetto è «eterozigote», mentre nel caso in cui la coppia di alleli fosse identica si parla di «omozigote».
Da notare che quando si determina un assetto genetico su un campione o reperto non c’è modo di sapere quale allele sia stato trasmesso dalla madre e quale dal padre, a meno che anche questi soggetti non siano sottoposti a esame per lo stesso marcatore genetico.
All’art. 22, comma 3, del regolamento vengono indicate le tipologie, quindi marcatori STR autosomici, marcatori STR del cromosoma Y (Y-STR) e marcatori STR del cromosoma X (X-STR), nonché del DNA mitocondriale (mtDNA).
Perché proprio i microsatelliti? Per pura convenienza, ecco perché! La scelta si è infatti orientata su queste zone del DNA perché offrivano le migliori garanzie da svariati punti di vista, caratteristiche che lo stesso regolamento indica al comma 4 dello stesso articolo 22:
- sono contenuti in frammenti di DNA piccoli, tra 100 e 400 bp [1], quindi c’è più probabilità di trovarli intatti in reperti biologici degradati dove il DNA tende a frammentarsi;
- si trasmettono in modo mendeliano, cioè in maniera casuale dal padre e dalla madre;
- sono indipendenti, purché la loro distanza sui cromosomi sia sufficientemente ampia;
- possiedono un elevato valore informativo, con eterozigosità superiore al 70% [2];
- possiedono molti alleli, quindi è probabile trovare molte persone con assetti genetici diversi: si dice che sono «altamente discriminativi»;
- sono molto studiati ed esistono molti dati di frequenza nelle varie popolazioni del mondo;
- si possono analizzare contemporaneamente, fino a 20-30 e anche più, in una singola reazione, opportunità molto utile perché spesso la ridotta quantità della traccia consente soltanto una o due ripetizioni dell’esame.
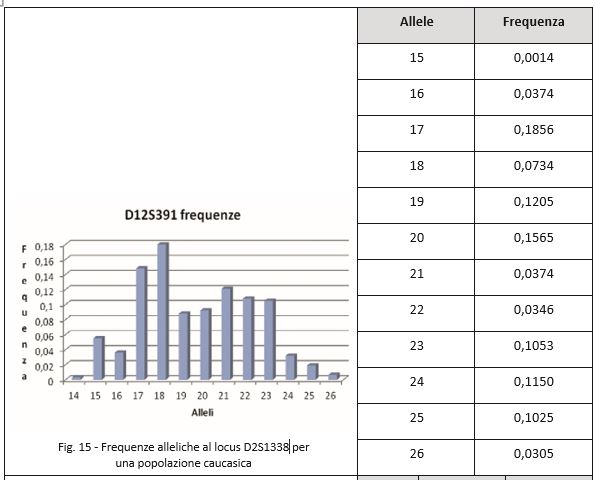
L’utilità dei microsatelliti si basa sulla conoscenza della frequenza nella popolazione di riferimento, cioè nella modalità con cui i vari alleli sono distribuiti negli individui. Queste informazioni si ottengono da studi popolazionistici, cioè si effettuano dei campionamenti su una popolazione casuale di soggetti non imparentati e si verifica il numero e il tipo di alleli osservati, con una statistica finale che fornisce una stima accurata, in quel gruppo di persone. Questi dati sono usati per stabilire quanto un profilo genetico sia raro in quella popolazione, poiché per vari principi della genetica formale è noto che le frequenze alleliche restano pressoché costanti nel corso delle generazioni.
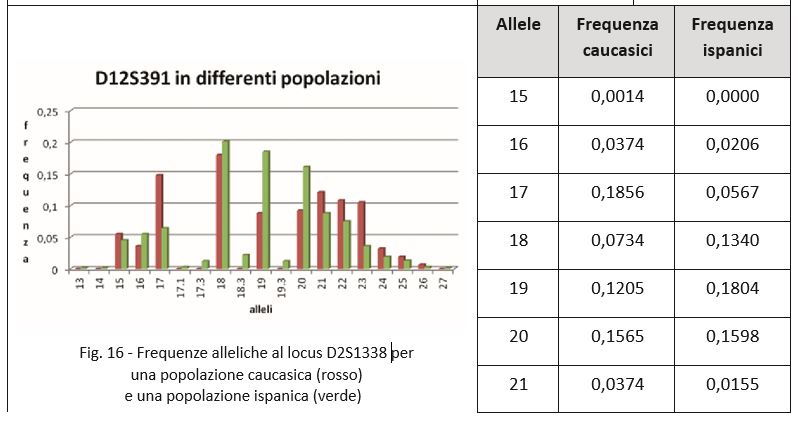
Nella pratica la differenza nelle frequenze geniche tra le popolazioni non è così elevata, anche tenendo conto del fatto che normalmente i dati relativi ai profili genetici si riferiscono a molti marcatori. Eventuali differenze registrate per alcuni marcatori sono riequilibrate per altri.
La presenza di molti alleli a ciascun marcatore ne spiega l’utilità per l’individuazione personale, fondamentale differenza rispetto ai classici sistemi gruppo-ematici, come il sistema AB0 e Rh che prevedono solo poche forme alternative e che sono stati usati per anni, prima della scoperta del DNA.
Vi sono alcuni marcatori del DNA costituiti da un numero estremamente elevato di alleli e che offrono quindi, a priori, cioè prima del loro utilizzo, una elevata informatività.
Il numero dei microsatelliti nel genoma umano è enorme. La comunità internazionale si è via via concentrata su un numero definito di marcatori, in modo tale che sia possibile lo scambio di informazioni da un capo all’altro del mondo, tra laboratori e Banche dati diverse. La Fig. 19 riporta i marcatori utilizzati nel database statunitense, detto Combined DNA Index System (CODIS), con la loro localizzazione cromosomica.
Il regolamento attuativo della legge sulla Banca dati fa riferimento, all’art. 22, Amplificazione del DNA al tipo di marcatori da utilizzare. Infatti, al comma 2 si fa riferimento ai nomi riportati nelle raccomandazioni dell’European Network of Forensic Science Institutes (ENFSI), utilizzati dall’Interpol e contenuti nella Risoluzione del Consiglio dell’Unione Europea n. 2009/C 296/01, e successive modificazioni, in parte sovrapponibili al CODIS. Essi costituiscono la serie europea standard (European Standard Set – ESS).
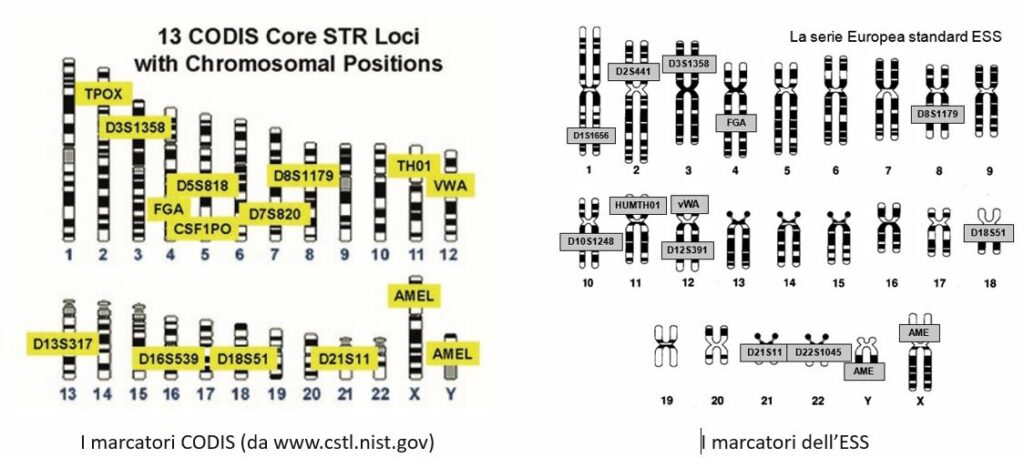
L’ESS è costituita dai seguenti dodici marcatori: D3S1358, vWA, D8S1179, D21S11, D18S51, HUMTH01, FGA, D1S1656, D2S441, D10S1248, D12S391 e D22S1045. Per l’analisi forense del DNA, gli Stati membri sono dunque invitati a impiegare almeno i marcatori del DNA che costituiscono l’ESS, allo scopo di facilitare lo scambio dei risultati dell’analisi del DNA.
[1] Cf. E.K. Hanson – J. Ballantyne, RNA profiling for the identification of the tissue origin of dried stains in forensic biology, in Forensic Science Review (2010)22, 145-157.
[2] F.S. Collins et al., Variation on a theme: cataloging human DNA sequence variation, in Science (1997)278, 1580-1581.
[3] La classificazione fa parte di varie raccomandazioni dell’ISFG; cf. per es. W. Bär et al., DNA recommendations. Further report of the DNA Commission of the ISFG regarding the use of short tandem repeat systems., in Forensic Sci Int (1997)87/3, 179-184.