Per comprendere i nostri errori dobbiamo sapere come pensiamo. Più in generale, chi ha un buon grado di metacognizione riesce a capire quando le sue performances non sono ottimali (self-monitoring). E così sarà in grado di fornire tutti i risultati possibili del test del DNA in maniera attendibile.
Ritornando al flusso delle analisi, con l’elettroforesi è stata generata una serie di elettroferogrammi, ciascuno contenente molte informazioni, per una ventina di marcatori o anche più. Nei casi reali spesso è possibile che siano generati decine di profili genetici su altrettanti prelievi e quindi si ha a che fare con una grossa mole di dati, con centinaia di marcatori da controllare e da confrontare. Il passaggio obbligato è quindi la trasformazione del risultato elettroforetico in tabelle nelle quali siano riportati, per ciascun marcatore, gli alleli dei singoli polimorfismi. I software associati agli strumenti sono in grado di generare automaticamente dei report e certamente vi sono integrazioni sempre più efficienti tra piattaforme analitiche per evitare errori tipici delle trascrizioni manuali.
È sempre opportuno, comunque, il controllo da parte di un altro operatore, ma a volte può non bastare.
Effettuare valutazioni su profili e ancor peggio comparazioni tra elettroferogrammi induce l’analista nell’euristica della rappresentatività.
Più in generale, conversando con i colleghi più esperti di genetica forense molti, di fronte a un profilo genetico, si diranno confidenti di poterne giudicare la bontà semplicemente guardandolo. Si fidano del loro Sistema 1 e della loro esperienza; e molto spesso non sbagliano.
Tuttavia, i problemi della genetica forense sono spesso difficili da risolvere senza l’uso delle probabilità e in questo il Sistema 1 non è efficace, per cui l’uso delle sole risposte euristiche in sostituzione al ragionamento accurato, proprio del Sistema 2, produce danni gravi. Quando poi i dati complessivi sono molti, l’urgenza è pressante e l’ansia sale, può capitare di trovare delle scorciatoie mentali assolutamente inappropriate.
L’uso delle tabelle non è dunque solo un passaggio tecnico che serve a trasformare un risultato di tipo grafico in un dato alfanumerico, ma una transizione logica che include i criteri di accettabilità del metodo e prepara alla fase valutativa successiva.
I risultati tipici delle valutazioni sono dunque tre: l’esclusione, l’attribuzione e l’inconclusività.
9.1.1. L’esclusione
Il seguente è il procedimento logico nella valutazione di due profili del DNA generati da due tracce e comparati tra di loro per capire se provengano dalla stessa persona.
Nella tabella sottostante ciascun profilo è contrassegnato da un codice alfanumerico che può essere anche un codice a barre, comunque un codice anonimo non equivoco.
| N. | Amelogen | D3S1358 | vWA | FGA | D8S1179 | D21S11 | D18S51 | D2S441 | TH01 |
| A1 | X-Y | 14-15 | 15-16 | 18-20 | 8-9 | 28-29 | 9-11 | 9-12 | 6-9 |
| B2 | X-Y | 14-17 | 15-16 | 18-20 | 8-11 | 29-29 | 11-11 | 11-12 | 6-7 |
L’esame comparativo si fa marcatore per marcatore.
| N. | Amelogen | D3S1358 | vWA | FGA | D8S1179 | D21S11 | D18S51 | D2S441 | TH01 |
| A1 | X-Y | 14-15 | 15-16 | 18-20 | 8-9 | 28-29 | 9-11 | 9-12 | 6-9 |
| B2 | X-Y | 14-17* | 15-16 | 18-20 | 8-11* | 29-29* | 11-11* | 11-12* | 6-7* |
La comparazione mostra che, su otto marcatori autosomici esaminati, sei risultano incompatibili (sono quelli indicati dall’asterisco). Reperti provenienti dallo stesso soggetto devono avere medesimo profilo genetico per tutti i marcatori; se così non è, allora essi derivano da soggetti diversi. Negli esami comparativi è sufficiente che anche un solo marcatore abbia un assetto genetico diverso, da poter ritenere due campioni biologici di diversa origine, anche se nella pratica, qualora due tracce abbiano diversa provenienza, le incompatibilità evidenziate sono numerose.
Il risultato di cui sopra permette di emettere un giudizio di «esclusione» rispetto al fatto che le due tracce provengano dallo stesso individuo. La contemporanea presenza di alcuni marcatori con medesimo assetto genetico è quindi imputabile alla casualità o, più probabilmente, alla frequente ricorrenza nella popolazione di quel particolare assetto del DNA.
Il risultato di esclusione è considerato perentorio e non richiede alcuna considerazione probabilistica, peraltro possibile anche a posteriori. Mogli sospettose, ma anche amanti tradite, talvolta cercano riscontri attraverso le analisi di laboratorio ai sospetti nei confronti dei loro compagni. I quesiti sono i più curiosi, ma sempre sottendono drammi familiari di cui chi effettua gli accertamenti non può avere reale cognizione. È per questo motivo che tali richieste dovrebbero essere vagliate con attenzione prima di essere accolte, perché gli esiti degli esami giungono direttamente nella disponibilità del committente e non si può avere che una timida percezione di quelli che saranno gli esiti pratici.
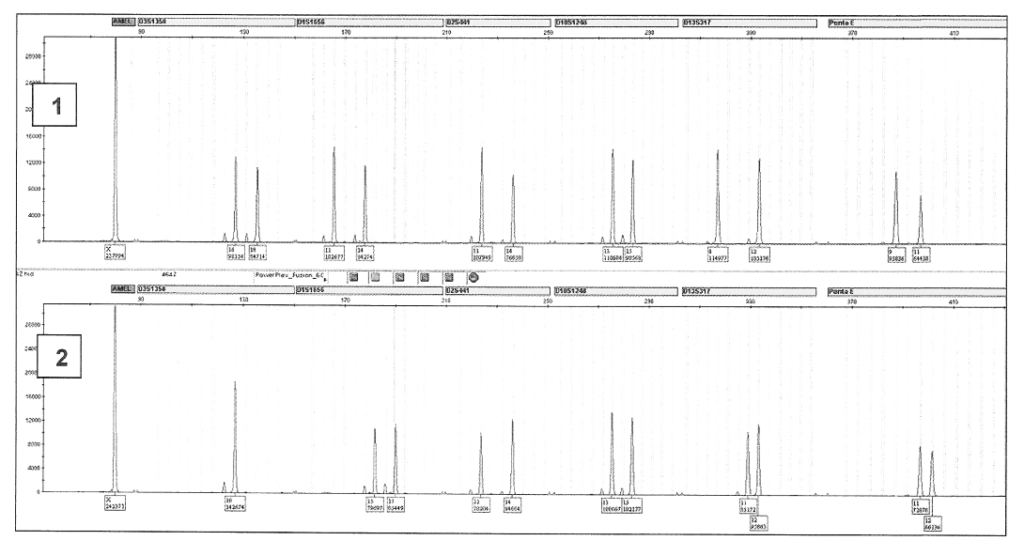
Una donna portò un asciugamano rinvenuto fuori posto nel proprio appartamento, sul quale aveva trovato delle «strane macchie biancastre», chiedendo di verificare se si trattasse di materiale umano, determinandone il profilo genetico e poi, in caso positivo, di procedere alla comparazione con un campione della propria saliva. Effettivamente fu riscontrata la presenza di materiale biologico sull’asciugamano, appartenente a una donna, che però era senza dubbio diversa dalla signora che aveva formulato il quesito:
| Locus | Tracce sull’asciugamano | richiedente |
| Amelogenina | X, X | X, X |
| D3S1358 | 16, 18 | 16, 16 * |
| D1S1656 | 11, 14 | 15, 17 * |
| D2S441 | 11, 14 | 11, 14 |
| D10S1048 | 13, 15 | 13, 15 |
| D13S317 | 8, 12 | 11, 12 |
| Penta E | 9, 11 | 11, 12 * |
Nei casi giudiziari l’accertamento può essere risolutivo, ma altre volte può non essere sufficiente alla ricostruzione esatta dell’episodio. In questi casi gli accertamenti prevedevano comparazioni dirette, ma in casi più complessi non sempre è disponibile un campione di riferimento certo della persona da identificare. Conoscendo le regole della trasmissione dei caratteri ereditari e in particolare il dato che l’informazione genetica viene trasmessa dai genitori ai figli, attraverso lo studio dei marcatori genetici è possibile seguirne la segregazione, e quindi utilizzare come campioni di riferimento i DNA prelevati a correlati disponibili.
9.1.2 L’attribuzione
«Adesso stiamo entrando nel campo delle ipotesi» disse il dottor Mortimer.
Artur Conan Doyle, Il mastino dei Baskerville
«Dica piuttosto nel campo dove soppesiamo le probabilità e scegliamo la più verosimile. Questo è il modo scientifico di usare l’immaginazione, ma abbiamo sempre una base di partenza materiale», rispose Sherlock Holmes.
Diamo adesso un’occhiata alla tabella qui sotto.
| N. | Amelog. | D3S1358 | vWA | FGA | D8S1179 | D21S11 | D18S51 | D2S441 | TH01 |
| 10-A | X-Y | 16-17 | 16-19 | 21-22 | 13-15 | 29-31 | 13-14 | 11-14 | 6-9.3 |
| 17-B | X-Y | 16-17 | 16-19 | 21-22 | 13-15 | 29-31 | 13-14 | 11-14 | 6-9.3 |
Il profilo dei campioni 10-A e 17-B è identico per tutti i marcatori, facendo ipotizzare che le tracce provengano dal medesimo individuo. Si dice che i due campioni sono tra loro compatibili o che vi è concordanza tra i profili genetici.
E’ possibile attribuire con certezza la traccia biologica a quel soggetto? Nel caso per esempio in cui una macchia di sangue abbia lo stesso profilo di un campione biologico dell’indagato? In poche parole, usando una terminologia spicciola: «È lui o non è lui?».
Certamente la compatibilità per tutti i marcatori è difficilmente spiegabile con il caso. Ma l’incertezza nella scienza non può essere risolta solamente dall’intuito e dal buon senso. Prima di condannare un sospettato il giudice vuole evitare di ricorrere a valutazioni soggettive o scorciatoie di ragionamento.
Sappiamo che c’è una tendenza all’«incorniciamento», perché l’ambito della decisione è influenzato dalla rappresentatività e la frequenza di un evento è giudicata tendenzialmente in base alla disponibilità dei suoi esempi.
La questione che si pone può essere trasposta in molti modi diversi, con lo stesso significato.
Qual è la probabilità che la concordanza derivi dalla casualità invece che dalla provenienza del reperto dall’indagato?
Per dare significato all’esame accertativo di tipo genetico è necessario transitare dalla stima della frequenza di un profilo del DNA, un po’ come molti anni prima aveva fatto Balthazard per le impronte digitali.
Cambia il tipo di variabilità, ma il concetto di rarità non è molto diverso.

Il più classico esempio per spiegare la probabilità è il lancio dei dadi. La probabilità che lanciando un dado esca, per esempio, il numero 4 è uno su sei (1/6). Questo vale per tutte le facce del dado – a patto che non sia truccato – e vale per tutti i lanci successivi. Così, la probabilità che in due lanci successivi entrambe le volte esca il numero 4, è il prodotto dei due eventi semplici, quindi 1/6 x 1/6, cioè 1/36. Questa probabilità si chiama composta. Gli eventi sono indipendenti e per ottenere una stima accurata del ripetersi dei due eventi si deve ricorrere al fattore moltiplicativo.
L’alto potere informativo dei marcatori del DNA rende rara l’occorrenza casuale di un medesimo assetto genetico nella popolazione. Le frequenze alleliche dei singoli marcatori sono note, pubblicate sulle più importanti riviste scientifiche e disponibili online.
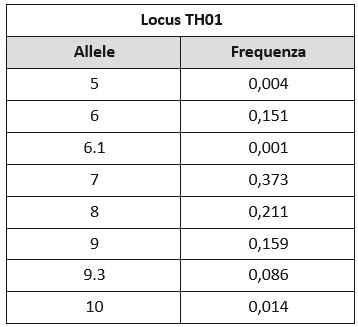
L’alto potere informativo dei marcatori del DNA rende rara l’occorrenza casuale di un medesimo assetto genetico nella popolazione. Le frequenze alleliche dei singoli marcatori sono note, pubblicate sulle più importanti riviste scientifiche e disponibili online. Per esempio, il locus TH01 è stato descritto come costituito da otto forme alleliche[1], ciascuna con una frequenza determinata nella popolazione analizzata.
[1] B. Budowle et al., Population genetic analyses of the NGM STR loci, in Int J Legal Med (2011)125, 101-109.
In base a queste frequenze e a regole di genetica di popolazione si può stabilire che l’assetto più comune per questo marcatore è 7-8 che ha una frequenza nella popolazione di 0,15. Ciò significa che effettuando l’analisi di questo marcatore in un gruppo di 100 persone non imparentate, circa 15 avranno il medesimo assetto genetico 7-8.
Per verificare quanto funzioni la genetica di popolazione, provate a chiedere a un gruppo abbastanza numeroso di persone qual è il gruppo sanguigno di ciascuno. Scoprirete intanto che alcuni non lo conoscono (!), ma se questa percentuale è bassa non avrete difficoltà a predire che ci sarà una numerosità consistente di gruppo 0 e gruppo A, a fronte di pochi B e rarissimi AB.

Se poi vi intriga la statistica amando il rischio, con un pubblico sufficientemente numeroso potreste dichiarare che scommettete che in sala almeno due persone nel pubblico sono nate nello stesso giorno dell’anno. È il noto «paradosso del compleanno» ideato nel 1939 da Richard von Mises. La probabilità che almeno due persone in un gruppo compiano gli anni lo stesso giorno è largamente superiore a quanto potrebbe dire l’intuito. già in un gruppo di 23 persone la probabilità è circa 0,51; con 30 persone essa supera 0,70 per arrivare addirittura a 0,97 con 50 persone.
Un’altra caratteristica fondamentale è che i marcatori autosomici sono stati scelti in modo tale che non possano influenzarsi gli uni con gli altri. L’assetto genetico di un marcatore non ha alcuna relazione con quello di un altro, anche se posizionato sullo stesso cromosoma. Purché sia sufficientemente distante in termini di unità fisiche genetiche. Si tratta di eventi indipendenti, come nel lancio successivo di due dadi. Quindi le frequenze genotipiche si possono moltiplicare tra loro. Si ottengono valori estremamente bassi rispetto alla possibilità di individuare un medesimo profilo con lo stesso identico assetto. Il locus dell’amelogenina non viene considerato in questa stima.
| REPERTO | D3S1358 | vWA | FGA | D8S1179 | D21S11 | D18S51 | D2S441 | TH01 | |
| 5-A | 16-17 | 16-19 | 21-22 | 13-15 | 29-31 | 13-14 | 11-14 | 6-9.3 | |
| Match probability | 0,12 | 0,052 | 0,07 | 0,093 | 0,018 | 0,062 | 0,188 | 0,118 | 2,0 x 10E-8 |
Il numero 2,0 x 10E-8 è definito «probabilità di condivisione casuale» (o match probability PM o random match probability RPM). Rappresenta la stima della diffusione del profilo genetico nella popolazione utilizzata per la scelta delle frequenze genetiche. Definizioni alternative di questo numero sono quella numerica, 0,000000020 oppure il riferimento alla sua diffusione attesa nella popolazione, quindi 1 su 41.496.000 di persone.
A questo proposito le differenze non sono significative tra etnie. Volendo è possibile effettuare stime accurate. Esistono oggi delle risorse telematiche libere e consultabili in maniera rapida, come ad esempio il sito dell’ENFSI DNA WG STR Population Database [1]. Qui sono riportate le differenti frequenze alleliche osservate in diversi studi.
Alcuni autori definiscono il modo in cui ci si aspetta che un evento osservato in un caso isolato si rifletta in tutti i soggetti appartenenti alla popolazione dalla quale il campione/reperto deriva, come «credere nella legge dei piccoli numeri» (belief in the Law of Small Number). A tale proposito divengono importanti le valutazioni che gli esperti fanno quando stimano la frequenza di un particolare profilo genetico nella popolazione. Il dato che si fornisce è effettivamente rappresentativo della reale diffusione di quel profilo nella popolazione da cui il campione deriva?
Si è appena detto che qualora sia determinato il profilo genetico per molti marcatori autosomici la differenza tra una popolazione e l’altra è minima e ampiamente assorbita dalla rarità del profilo genetico determinato. Certamente ciò vale qualora molti siano i marcatori caratterizzati in un profilo, mentre possono essere quantitativamente significative le differenze qualora i marcatori siano molto pochi. Una stima generale abbastanza rappresentativa della realtà è quella che assegna all’assetto di un qualunque marcatore del DNA una stima di 0,1 (10%). Già dall’esame di sette marcatori, come quelli necessari per le comparazioni in ambito nazionale nella Banca dati del DNA, i valori di PM sono ragionevolmente molto piccoli.
Utilizzando pannelli più ampi, con venti e più marcatori, questi numeri divengono significativamente più piccoli. Fino a raggiungere valori quasi imbarazzanti che non possono essere confrontati su scala terrestre.
La definizione di probabilità di condivisione casuale è dunque una stima teorica basata sulla conoscenza della genetica della popolazione. Come tale dovrebbe servire a trasmettere la convinzione che si tratti di caratteri rarissimi. Una cautela, però: più è potente l’esame, più siamo ingannati nella valutazione e nel giudizio.
560 miliardi è un numero effettivamente molto grande, se lo si paragona al numero di abitanti del pianeta. In questi casi alcuni assumono che si tratti di un «profilo unico», dimenticando che si tratta di una stima statistica, non di un numero reale. Questo è conosciuto come «l’errore dell’unicità» (uniqueness fallacy) [1]. Non sono disponibili i profili genetici di tutti gli abitanti della terra. Questo finora e forse per molto tempo, almeno se le altre nazioni non seguiranno l’esperienza recente del Kuwait!
Si può però stabilire quale sia la probabilità di trovare un altro profilo con quelle caratteristiche, escludendo ovviamente i gemelli identici. Per esempio, se la frequenza è 1 su 560 miliardi, la probabilità di trovarne un altro identico nella popolazione terrestre costituita da 7 miliardi di individui è circa 1 su 80, cioè circa l’1,2% [2].
9.1.3 I marcatori di lineage
Stime di questo tipo non si possono fare per i marcatori di lineage. Nel caso si esaminino, infatti, marcatori del cromosoma Y, si deve tener conto del fatto che questo tratto genetico viene trasmesso per intero inalterato nelle generazioni, «senza ricombinazione». Ciò significa che l’assetto dei marcatori del cromosoma Y resta praticamente immutato nel corso delle generazioni. Dunque, non è possibile stimare la probabilità di condivisione casuale di un profilo Y sulla base delle frequenze geniche, come si è visto per i marcatori autosomici.
In questo caso vengono valutate le frequenze degli «aplotipi», cioè della combinazione di diversi marcatori lungo il cromosoma. Per verificare la frequenza degli aplotipi individuali questo impone di studiare in una popolazione molti uomini, non essendo possibile avere informazioni circa le frequenze genetiche come per i marcatori autosomici. È per questo motivo che gli esami del cromosoma Y sono certamente molto meno informativi rispetto a quelli dei polimorfismi autosomici. Esiste un progetto europeo chiamato Y-Chromosome STR Haplotype Reference Database che raccoglie informazioni riguardo i più utili Y-STR utilizzati nella pratica forense. La stima delle frequenze viene registrata nelle varie popolazioni. Gestito da Lutz Roewer dell’Università di Berlino, rappresenta un punto di riferimento per tutta la comunità forense[3].
Vale la stessa cosa anche per le valutazioni riguardo alla frequenza degli aplotipi dell’mtDNA. In questo caso il punto di riferimento europeo è il laboratorio di Walther Parson dell’Università di Innsbruck[4].
In entrambi i casi la valutazione delle frequenze non è quindi esercizio banale. Possono essere discutibili da diversi punti di vista i valori finali che si ottengono, e quindi le probabilità finali di individualizzazione. Inoltre, in senso più generale, nel corso del processo le domande possono essere anche più precise.
Sebbene la valutazione del numero di volte che un profilo si riscontra in una popolazione, data dalla probabilità di condivisione casuale, possa essere sufficiente a soddisfare il maggior numero di volte i problemi di individualizzazione, vi sono molte questioni che non possono essere risolte, se non con un approccio diverso.
Ciò avviene il più delle volte nell’esame delle misture o quando siano coinvolti nelle vicende soggetti correlati geneticamente con il sospettato. Così, il giudice può voler valutare, una volta acquisito un profilo genetico e i DNA di confronto, quanto siano rilevanti ipotesi contrapposte. «Qual è la probabilità di trovare questo profilo se il sospetto è effettivamente colui che ha lasciato la traccia, rispetto alla probabilità di trovare questo profilo se qualcun altro che il sospetto sia il vero donatore della traccia biologica?». Scarsamente utilizzato nelle aule dei tribunali italiani, questo approccio sta guadagnando via via il proprio giusto spazio. E’ molto utile ai fini della valutazione della prova, sotto le diverse prospettive della difesa e dell’accusa.
9.1.4 Le stime statistiche delle evidenze genetiche
Data una macchia e la compatibilità del profilo risultante con quello dell’indagato, la parte pubblica può sostenere che la macchia provenga effettivamente dalla persona indagata. Il difensore può sostenere che, invece, la compatibilità osservata derivi dal fatto che uno sconosciuto, diverso dal proprio cliente, abbia effettivamente lasciato quel reperto biologico sulla scena del crimine. Quindi la compatibilità dei profili con il proprio cliente sia soltanto un effetto casuale del campionamento nella popolazione.
In questi casi si utilizza il «rapporto di verosimiglianza»(likelihood ratio o LR), per mezzo del quale viene confrontata l’ipotesi di identità contro quella di associazione casuale.
Se ad esempio dall’esame di un profilo genetico e dall’applicazione del calcolo si ottiene un valore LR = 200, si può asserire che la traccia è 200 volte più probabile se il sospettato ha lasciato la macchia sul luogo del delitto, rispetto a qualche altra persona sconosciuta. Maggiore è il valore di LR, maggiore è la forza a favore dell’identità contro quella dell’associazione casuale.
Nei casi più semplici il valore di LR è semplicemente il reciproco del valore di PM. Per cui quanto più bassa è la probabilità di condivisione casuale, tanto più alto il valore di rapporto di verosimiglianza. Tuttavia, quando il numero di marcatori tipizzati diminuisce o vi siano varie ipotesi alternative, più complesse e da esplorare con un metodo statistico accurato, il calcolo di questo termine deve essere sempre effettuato con diligenza.
Qui è fondamentale comprendere l’entità della misura effettuata e il suo significato, espresso appunto dalla forza dell’identificazione genetica.
Ricordate che questo risultato non fornisce, però, alcuna informazione riguardo alle modalità con cui si sia formata la traccia mista, né come, né quando. Per farlo non c’è altro modo che far riferimento alle esperienze della letteratura, se esistenti[5].
Alcuni giudici chiedono poi all’esperto di esprimere il risultato dei loro accertamenti in termini di probabilità. Richieste che pervengono praticamente in modo esclusivo dal rito civile, come visto nel caso dei test di paternità, raramente nell’ambito penale.
Eppure il teorema di Bayes potrebbe essere molto utile per esprimere giudizi in maniera obiettiva. In teoria quanto di meglio per chi debba assumere il gravoso onere di mettere insieme elementi circostanziali con i dati scientifici.
La già citata sentenza 18-06-2015 del Tribunale di Milano, sez. G.I.P., giudice Gennari, rappresenta un esempio concreto dell’utilizzo giudiziario del teorema applicato a un caso reale. Si tratta tuttavia di un esempio purtroppo episodico. L’utilizzo di tale formula matematica non è assolutamente comune. Si tratta probabilmente della prima volta in cui l’uso razionale del teorema di Bayes in ambito penale è stato utilizzato e descritto con così attenta precisione nelle motivazioni di una sentenza italiana.
Resta il grosso problema dell’attribuzione delle probabilità a priori, compito effettivamente difficoltoso. Proprio quando si tratti di trasferire in termini numerici aspetti difficilmente quantificabili, come quelli della vita di tutti i giorni. «Qual è la probabilità che l’indagato fosse sul luogo del delitto e non al lavoro il giorno del delitto?». Oppure: «Qual è la probabilità che il testimone abbia correttamente identificato il malvivente in quella giornata così piovosa e con uno dei lampioni della strada non funzionante?».
Per certi aspetti legati più strettamente alla materia, qualcosa si sta facendo. Specialmente per aspetti più legati alle probabilità di associazione di una traccia in certi contesti piuttosto che in altri. Quanto è probabile che i frammenti di DNA del fidanzato siano sotto le unghie della vittima per un trasferimento casuale invece che per difesa? Qual è la probabilità che siano stati trasferiti il giorno prima anziché cinque giorni prima del delitto? Per rispondere in modo scientifico a tali quesiti servono esperimenti e dati misurabili per raccogliere le probabilità a priori. È ben difficile poterlo fare per tutte le variegate forme con cui si generano le tracce in un delitto. Qui servirebbe la ricerca, un territorio nel quale si produce poco a livello internazionale, praticamente inesplorato nel contesto italiano.
Gli aspetti probabilistici della valutazione della prova genetica sono quindi certamente sottovalutati nel contesto della formulazione dei risultati. Sicuramente non vengono accreditati in un metodo di prova del DNA, almeno fino a oggi. Fanno parte di quelle attività soggettive nelle quali ogni esperto esprime il proprio modo di relazionare l’esito degli accertamenti. Sono ovviamente fondamentali rappresentando in definitiva il corollario valutativo presentato alle Corti, sul quale i giudici esprimeranno le proprie valutazioni formando il giudizio sulla ricostruzione storica di un fatto. I magistrati prenderanno decisioni diverse a seconda di come i dati saranno presentati.
Vi sono due idee da tenere a mente riguardo alla logica bayesiana e a come tendiamo a sconvolgerla. La prima è che le probabilità a priori contano anche in presenza di prove sul caso in questione: è un dato che spesso non è intuitivamente ovvio. La seconda è che l’impressione che abbiamo intuitivamente della diagnostica delle prove è spesso esagerata[6].
Daniel Kahneman suggerisce di fare due cose.
- ancorare il nostro giudizio della probabilità di un risultato a una probabilità a priori plausibile;
- mettere in discussione la diagnostica delle nostre prove.
Così l’uso della logica bayesiana, anche senza l’applicazione di regole matematiche complesse, evita la tendenza inconsapevole di farci credere nelle storie che ci raccontiamo da soli.
9.1.5 L’inconclusività
Le aspettative negli accertamenti forensi sono sempre alte da parte del cliente. Vi è sempre la percezione che la «prova regina» possa risolvere qualunque dubbio. Dunque si ripone nell’esperto una forte aspettativa di soddisfacimento di un bisogno reale. All’opposto, può crearsi da parte dell’analista la percezione di poter risolvere il caso giudiziario di turno. In una sorta di euristica affettiva che pone eccessivo valore alla propria attività professionale, alle proprie capacità, all’eccellenza del proprio laboratorio.
A volte, invece, le analisi possono avere esiti incerti, con profili non utilizzabili per valutazioni riguardo ad attribuzioni o esclusioni. Tale esito può scaturire per varie ragioni, tra cui profili genetici da basso numero di copie, campioni degradati, poche persone disponibili per i test genetici di confronto. Si tratta di esiti che naturalmente nessuno gradisce, ma possibili. Quando si è fatto tutto ciò che è possibile a livello analitico, adottando in maniera certosina il metodo dichiarato si deve arrendersi lla realtà dei fatti.
Si tratta di un esito dignitoso e non vi è alcuna ragione di alterare il percorso analitico delle proprie analisi per ottenere a tutti i costi, comunque, un risultato. Tra l’altro, ciò costituisce un venir meno agli obblighi di lealtà e correttezza imposti dal proprio ordine professionale (per esempio, per il biologo l’art. 5, c. 1 [7]), salvo il configurarsi di un vero e proprio reato penale (art. 373 c.p.) laddove il professionista svolga il ruolo di perito.
[1] J. David – D.J. Balding, Weight-of-evidence for Forensic DNA Profiles, John Wiley & Sons, 2005, 148, 32.
[2] Se il profilo genetico G di un individuo ha una probabilità PG, la probabilità di trovare almeno un altro individuo che abbia lo stesso profilo in una popolazione di N individui non correlati è 1 – (1 – PG)N. Una stima approssimata di questa probabilità può essere ottenuta dalla semplice espressione NPG, come suggerito in National Research Council, The Evaluation of Forensic DNA Evidence, National Academy Press, Washington DC 1996.
[3] https://yhrd.org/
[4] http://empop.online/
[5] Peter Gill fornisce una raccomandazione: «Se uno scienziato fornisce un’opinione, questa deve essere qualificata da prove sperimentali. Se un’opinione è espressa in modo che appaia senza sostegno di prove (in termini di peer-review o analisi di dati) essa non può essere verificata obiettivamente, quindi non ha basi scientifiche» (da Misleading DNA evidence, 79; traduzione dell’autore).
[6] D. Kahneman, Thinking, Fast and Slow (ed. it.: Pensieri lenti e veloci, trad. di L. Serra, Mondadori, Milano 2012, 170-171).
[7] Codice Deontologico dell’Ordine Nazionale dei Biologi, adeguato alla legge n. 148 del 14-09-2011, D.P.R. del 7-08-2012 n. 137, approvato dal Consiglio dell’Ordine con delibera n. 83 del 27-02-2014; http://www.onb.it/2014/09/17/codice-deontologico-della-professione-di-biologo/#sthash.HkOcwA31.dpuf